Below is a system design interview document template you can reuse for almost any problem. It’s written in the same “requirements → architecture → scale math → failure modes → costs” flow interviewers expect
1) Problem Statement
Build <SYSTEM> that allows <USERS> to <DO X> with <KEY CONSTRAINTS> (e.g., near real-time, large scale, compliance, multi-region, etc.).
Out of scope (explicit):
<items>(e.g., admin UI, billing, analytics v2, etc.)
2) Requirements
2.1 Functional Requirements
List what the system must do (user-visible behaviors):
- User actions
- Users can
<create/update/delete><entity> - Users can
<search/browse/filter><entity> - Users can
<upload/download><assets>(images, documents, videos)
- Users can
- System behaviors
- Validate inputs (schema + business rules)
- Persist data reliably
- Trigger background processing (transcoding, ML, indexing, notifications)
- Provide status tracking (PENDING → PROCESSING → DONE/FAILED)
- Notifications
- Notify users via
<email/SMS/push/webhook>on events<...>
- Notify users via
- Admin / Ops
- Observability: dashboards + alerts
- Abuse controls (rate limits, fraud checks)
2.2 Non-Functional Requirements
Write them as targets (SLOs) + assumptions.
- Scale
- DAU:
<...> - Peak RPS:
<...>(read/write split) - Upload volume:
<...>GB/day - Data growth:
<...>entities/day
- DAU:
- Latency
- P50/P95 API latency targets: e.g., P95
<200ms>for reads;<400ms>for writes - Background job SLA: e.g., 99% completed within
<5 minutes>
- P50/P95 API latency targets: e.g., P95
- High Availability
- Availability target: e.g., 99.9% (or 99.99%)
- Multi-AZ required; multi-region optional/required?
- Accuracy / Consistency
- Strong consistency needed for
<...>(payments, inventory) - Eventual consistency acceptable for
<...>(feeds, analytics)
- Strong consistency needed for
- Budget
- Monthly ceiling:
<$X> - Cost priorities: compute vs storage vs egress
- Monthly ceiling:
- Security & Compliance
- Auth: OAuth/OIDC/JWT, mTLS for service-to-service
- Encryption: TLS in transit + KMS at rest
- PII handling, audit logs, retention policies
- OWASP, WAF, secrets management
3) System Requirements (What the system must do)
Turn requirements into capabilities:
- API Layer
- CRUD endpoints + pagination + filtering
- Idempotency keys for writes
- Rate limiting & quotas
- Object Storage
- Store large blobs (images/docs/videos) in S3/Blob Storage
- Use pre-signed URLs to avoid proxying large files through API servers
- Virus scanning / content moderation hooks (async)
- Database
- Store structured metadata + relationships
- Indexing strategy for primary queries
- Queue + Workers
- Durable queue (SQS/Rabbit/Kafka) for background jobs
- Workers process jobs with retries, exponential backoff, DLQ
- Notification Service
- Fanout events and deliver via email/SMS/push/webhook
- Retry + DLQ + provider failover
- Archival
- Move cold data to cheaper tiers and/or warehouse for analytics
4) Back-of-Envelope Estimations (Sizing + Cost Drivers)
4.1 Traffic
Assume:
- Peak RPS =
avg_rps * burst_factor avg_rps = daily_requests / 86400
Example format:
- DAU: 1M
- Requests/user/day: 20 → 20M req/day
- avg_rps = 20,000,000 / 86,400 ≈ 231 rps
- Peak factor 10x → ~2,300 rps peak
4.2 Storage
Break into:
- DB metadata
- entity size ≈
<N bytes> - writes/day ≈
<X> - annual size ≈
N * X * 365
- Object storage
- avg file size:
<...>MB - uploads/day:
<...> - annual:
size * count * 365
Also note egress cost (often the surprise):
- downloads/day * avg size → TB/month out
4.3 Queue & Workers
- Job rate:
jobs/secderived from writes/uploads - Worker throughput:
jobs/sec/worker - Required workers:
ceil( job_rate / throughput_per_worker )
Scaling parameter (you asked for it):
- If jobs are durable and each worker does ~
tjobs/sec, then:workers_needed ≈ QueueDepth / TargetDrainTimeSeconds / t
- Or simpler:
workers_needed ≈ QueueDepth / JobsPerWorkerInTargetWindow
4.4 Networking / Messaging
- SQS cost driver: requests (Send/Receive/Delete)
- Kafka cost driver: broker hours + storage + inter-AZ replication
- Large payloads: store in object storage; queue only references (URI + checksum)
5) API Design (Typical)
Define core endpoints (example style):
POST /entities # create (idempotent)
GET /entities/{id} # fetch one
GET /entities?filter=&sort=&page= # list / filter / paginate
POST /uploads/presign # returns a pre-signed URL + key
GET /entities/{id}/status # processing status
POST /jobs/{id}/status # update job status
POST /webhooks/register # subscribe to eventsNotes interviewers like:
- Pagination: cursor-based for large datasets
- Rate limiting: token bucket per user/client
- Idempotency key on create/payment-like actions
6) Data Model (Core)
Show primary tables and important indexes.
Example template:
Entity
id PK
user_id FK
status
created_at
updated_at
INDEX (user_id, created_at DESC)
INDEX (status, updated_at) -- if polling by status
Asset
id PK
entity_id FK
storage_key
size
checksum
mime_type
created_at
INDEX (entity_id)
Job
id PK
type
entity_id
status
attempts
next_run_at
created_at
INDEX (status, next_run_at)7) Architecture
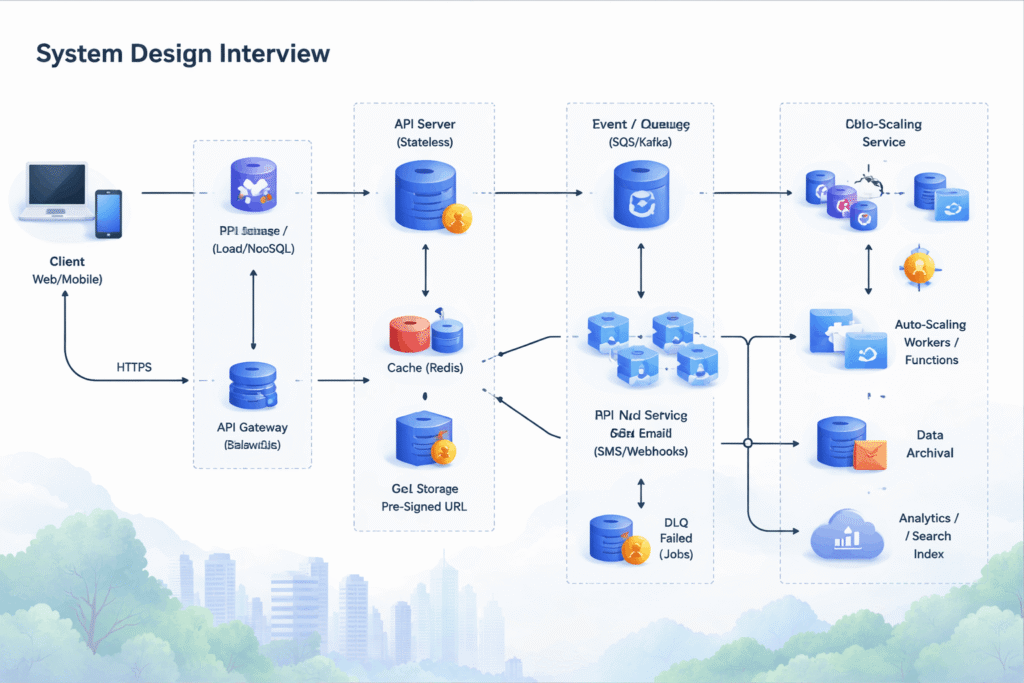
7.1 Diagram (text diagram you can redraw on a whiteboard)
Client (Web/Mobile)
|
| HTTPS
v
API Gateway / Load Balancer
|
v
API Service (stateless)
|------------------------|
| |
v v
Database (SQL/NoSQL) Cache (Redis)
|
v
Object Storage (S3/Blob) <--- via Presigned URL (upload/download)
|
v
Event / Queue (SQS/Kafka)
|
v
Workers / Functions (autoscaled)
| |
| +--> DLQ (failed jobs)
|
+--> Notification Service (email/SMS/push/webhook)
|
+--> Search Index / Analytics / Warehouse (optional)
|
+--> Archival (Glacier/Cold tier) (lifecycle policies)
7.2 Sync vs Async (explicit)
Synchronous path (user waiting):
- Validation
- Write metadata record
- Return ID + status + presigned URL (or accept callback)
Asynchronous path:
- Heavy compute: image/video processing, ML inference, search indexing
- Deliver notifications
- Fraud/abuse scans
- Large fanout events
Rule of thumb:
- If it must complete in <300–500ms, keep it sync.
- If it may take seconds+ or has variable runtime, push async.
8) Core Workflows
Workflow A: Upload + Process (with pre-signed URL)
- Client calls
POST /uploads/presign→ API returns{upload_url, object_key} - Client uploads directly to S3/Blob using the presigned URL
- Storage emits event (or client calls finalize endpoint)
- API/Listener enqueues job:
PROCESS_ASSET(entity_id, object_key) - Workers process:
- download asset (or stream)
- transform/scan
- write results to DB
- update status to DONE
- Notification emitted (optional)
Workflow B: Create Entity (idempotent)
- Client calls
POST /entitieswithIdempotency-Key - API checks idempotency table/cache
- API writes entity + emits event to queue
- Returns entity_id immediately
- Async processors do enrichment/index/notify
9) Queue, Retries, DLQ, and Failure Handling
9.1 Message format
Keep messages small:
{
"job_id": "...",
"entity_id": "...",
"object_key": "...",
"type": "...",
"trace_id": "...",
"created_at": "..."
}Store large payloads in object storage; put only references (key + checksum) in the message.
9.2 Retry Strategy
- Retry on transient failures: network, throttling, timeouts
- Exponential backoff + jitter
- Cap attempts (e.g., 5–10) then send to DLQ
- Store
attempt_count,last_error,next_run_at
9.3 Dead Letter Queue (DLQ)
- Every job type has DLQ with:
- alarm on DLQ growth
- replay tool (manual/automated)
- poison-pill detection (same job always failing)
9.4 Idempotency in workers
Workers must be safe to retry:
- Use job idempotency keys
- Check if output already exists before writing
- Use “upsert” or conditional writes
9.5 Notifications on failures
- If job fails permanently → write status FAILED + notify user/admin
- If queue age grows beyond SLA → alert ops
10) Autoscaling (Queue Depth / Workers)
10.1 Scaling rule
Let:
D = queue deptht = avg processing time/job (seconds)S = target drain time (seconds)(e.g., 120s)workers_needed ≈ ceil(D * t / S)
Or, if you know per-worker throughput:
- throughput per worker =
1/tjobs/sec - workers =
ceil( D / (S * (1/t)) ) = ceil(D * t / S)
10.2 Queue depth vs “oldest message age”
Use both:
- Depth handles volume
- Oldest age handles “stuck” or slow processing
10.3 Prewarming workers (explicit)
- Keep a small warm pool (min instances)
- Provisioned concurrency (serverless) or minimum ASG size (VM/containers)
- Load common models/config at startup
- Health-check gates to avoid cold-start storms
11) Data Archival and Retention
- Define retention per data type:
- hot: last 30–90 days in primary DB
- warm: older in cheaper storage / read replica
- cold: object storage lifecycle to cold tier
- DB archival:
- partition by time
- move old partitions to archive DB/warehouse
- Audit logs:
- append-only store, immutable retention
12) Security
- AuthN/AuthZ: JWT/OIDC + RBAC/ABAC
- Least privilege IAM roles
- Pre-signed URL constraints:
- short expiry
- content-type + size limits
- key prefix scoping per tenant/user
- Encryption:
- TLS everywhere
- at-rest with KMS-managed keys
- PII:
- field-level encryption where needed
- tokenization if required
- Abuse:
- WAF, IP reputation, rate limits
- signed webhooks, replay protection
13) Observability & Operations
- Metrics:
- API: latency (P50/P95/P99), error rates
- Queue: depth, oldest age, DLQ depth
- Workers: success/fail, retries, processing time
- Logs:
- structured logs with trace_id
- Tracing:
- distributed tracing across API → queue → worker
- Alerts:
- SLO burn, DLQ growth, queue age threshold, DB CPU/storage
14) Tradeoffs & Alternatives (always include)
- SQL vs NoSQL
- SQS vs Kafka
- Serverless workers vs containers
- Strong vs eventual consistency
- Push vs pull model for status updates (websockets vs polling)
15) Interview Close
Summarize:
- How the design meets latency/scale/availability
- Biggest risks (egress cost, hot partitions, long-running jobs)
- Next steps (load testing, schema evolution, chaos testing)